

AI Data Modeling - Intro
For decades, organizations have built sophisticated systems to manage their data. We've created entity-relationship diagrams, dimensional models for analytics, and detailed data dictionaries. These tools helped us understand, organize, and govern the information flowing through our operations.
Then AI entered the workplace, and something fundamental shifted.
The Shifting Landscape
Today's AI systems process our data in ways traditional models weren't designed to represent. A customer service chatbot interprets natural language, retrieves relevant context, and generates responses. An accounts payable system reads invoices as images, extracts structured data, and flags anomalies. A compliance reviewer summarizes hundreds of pages of regulations into decision criteria.
These aren't just new features bolted onto old systems. They represent a fundamentally different relationship between our data and our processes.
But here's what makes this challenging: our existing data, and the teams who manage it, remain essential. We can't throw away decades of institutional knowledge about data quality, security policies, and integration patterns. We need to reconcile what we've always done with what's now possible.
This isn't a replacement story. It's a reconciliation story.
The Economic Imperative
The economic implications are substantial. Organizations face a choice: continue scaling human effort linearly with workload, or develop AI augmentation capabilities that scale logarithmically.
Consider a municipal government processing 10,000 permits annually with 45 minutes of clerk time each - that represents 7,500 person-hours. AI-assisted verification might reduce this to 10 minutes per permit: 1,700 hours. That's a 77% reduction in processing time, freeing staff for higher-value work like applicant consultation and policy development.
But capturing that value requires deliberate design, not ad-hoc experimentation. Without clear methodology, pilot projects succeed but don't scale. Individual teams solve the same problems differently. Knowledge stays trapped in people's heads rather than becoming organizational capability.
AI data modeling provides the framework to turn isolated successes into repeatable value.
What's Changed: New Data Realities
AI introduces patterns that traditional data modeling doesn't naturally express:
Unstructured data has become primary input
Word processing documents, PDFs, scanned images, and email threads now drive critical business processes. Where we once designed intake forms with structured fields, we now accept whatever format the data arrives in and let AI extract what we need.
Text instructions perform data transformation
A carefully written prompt to an AI model does the same job as a SQL query or data transformation script: it takes input and produces structured output. But unlike SQL, these prompts are written in natural language, produce non-deterministic results that must be validated, and require a different kind of expertise to write well.
Context windows function as data containers
When we send information to an AI model, we must decide: what background information does it need? This isn't just about the immediate input - it's about bundling the right context. That's an architectural decision with major implications for cost, security, and accuracy.
The context challenge has spawned an entire toolkit of solutions.
| Challenge | Solution |
|---|---|
| Need to fit more information into limited token windows? | Context compression techniques extract maximum meaning from minimum space. |
| Want to avoid front-loading everything? | Dynamic context via tools lets models pull information only when needed. |
| Drowning in documentation? | Vector databases enable semantic search that finds relevant needles in informational haystacks. |
| Building user-facing applications? | UI-driven context awareness ensures the AI understands not just what users ask, but where they are in their workflow. |
These aren't competing approaches - they're complementary strategies that successful AI solutions weave together.
From an application design perspective, sophisticated prompts are first-class architectural components - not afterthoughts. At nSymbol we routinely work with prompts spanning hundreds or thousands of lines, representing as much complexity and business logic as multi-class Java applications or comprehensive SQL scripts. Just as backend development has established patterns and best practices, effective prompt engineering follows recognizable patterns too. Smart organizations develop these patterns internally and continuously refine them by studying external innovations.
Confidence scores replace binary success
Traditional validation gave us pass/fail results. AI gives us probabilities. A document classification might be 92% confident. Is that good enough to route automatically, or does it need human review? These thresholds become part of process design.
Prompt libraries and model versions need governance
When a well-crafted prompt becomes standard practice in your organization, it's a knowledge asset. When you switch AI vendors or upgrade model versions, it's a change that needs testing and documentation. From this perspective it looks a lot like database migration, or operating system upgrades, that we've been managing successfully for decades. We need to expect glitches, resolve glitches, and proactively avoid glitches.
Machine readable prompt libraries solve a big part of this challenge. You can label prompts according to purpose (e.g., classify, summarize, interpret, correlate) and then work with these groups. If an AI model changes to offer an attractive capability-cost combination, you can quickly determine impact across many prompts and prepare a testing plan. Searching for prompt reuse opportunities becomes easier as well.
What Hasn't Changed: Core Principles Still Apply
Despite these new patterns, fundamental data management principles remain critical:
- Security and privacy compliance matter more than ever, with new complexity when AI services process protected information.
- Audit trails and data lineage still answer "How did we arrive at this result?", even when AI is involved in the process.
- Data quality principles haven't changed. Garbage in, garbage out applies to AI systems too.
- Integration challenges persist, now with AI services as additional integration points.
- Human expertise remains irreplaceable for context, judgment, and complex decision-making.
We'll explore how these enduring principles shape AI data flow design in the next article.
The risk landscape has actually expanded. A traditional data breach exposes stored information. An AI workflow breach can expose your prompts (proprietary business logic), training data, conversation history, and behavioral patterns. An audit might reveal that sensitive data flows through AI services you didn't know were in use, or that your carefully designed security controls have gaps you never documented.
Without explicit AI data modeling, you may not even know which systems are touching sensitive data through which AI services. This isn't theoretical risk - it's a governance gap that auditors, regulators, and security teams will eventually expose.
The AI Data Modeling Opportunity
This is where AI data modeling comes in. It's not a new discipline made from scratch; it's an extension of data management practices to explicitly account for AI components.
Consider these questions that traditional data models don't help us answer:
- Where in your workflows could AI assist with data processing?
- What AI capabilities (extraction, classification, summarization) are transferable across different processes?
- Which of your successful prompts should be shared across teams?
- Where do humans review AI output, and what do they need to make that review effective?
- How do you ensure AI touches sensitive data only in compliant ways?
Some might ask: "Why do we need formal modeling? Can't teams just experiment with AI and see what works?"
Pure experimentation works initially. Individual teams adopt tools, write prompts, solve immediate problems. Early wins come quickly.
But this approach creates hidden costs: teams duplicate effort solving the same problems independently. Security practices stay inconsistent across the organization. Model usage goes ungoverned. Successful prompts remain trapped in individuals' heads. When someone leaves, their expertise leaves with them. When a model changes, nobody knows which workflows might break.
AI data modeling isn't about constraining innovation - it's about making successful innovations transferable, governable, and sustainable. It's the difference between having five teams each solve document extraction independently, versus solving it once and deploying it five times.
AI data modeling gives us frameworks and visual languages to answer these questions clearly.
A Methodology for Reconciliation
This article series introduces key concepts that help bridge traditional data management and AI-augmented workflows:
AI Capability Patterns
We need a way to identify reusable AI skills. "Entity extraction" works the same way whether you're pulling dates from building permits, claim amounts from invoices, or medication names from medical records. Cataloging these patterns helps teams share expertise and avoid reinventing solutions.
Prompt Engineering as a Discipline
Prompts should be treated like data transformation logic, because that's what they are. Well-written prompts deserve the same rigor as SQL queries: clear requirements, testing, version control, and documentation.
Catalog Systems
Having quick success in using AI is awesome. As it happens more often, you quickly become aware of the need to organize prompts, document schemas, and provide AI configurations in machine-readable format. Prompt catalogs can enable automation, ensure consistency, and create institutional memory about what works.
AI Skills Taxonomy
Building an AI Skills Taxonomy can help organizations move from scattered experiments to shared capability. When someone masters "medical record summarization," that skill might apply to legal case summaries or engineering inspection reports. Cataloging skills that your team has attained enables knowledge transfer.
Data Flow Visualization
One of the more valuable outputs of AI Data Modeling are traditional data flow diagrams extended with AI-specific elements. These show which models process what data, where humans review results, how compliance requirements are met, and more. Making AI touchpoints visible helps teams communicate and identify risks.
Human-AI Workflow Design
We need to establish clear collaboration patterns for humans working with AI. For each AI component you should address:
- Does a human approve before action (human-in-the-loop)?
- Does AI act with human monitoring (ai-in-the-loop)?
- What triggers human involvement?
These concepts work together to create a comprehensive view of how data, AI, and humans interact within your workflows.
What This Looks Like in Practice
Let's look at a concrete example that we know well at nSymbol: generating psychological assessment reports.
The traditional process involves a clinician administering standardized tests (like WAIS or WIAT), taking interview notes, and spending 2-10 hours writing a comprehensive report synthesizing all findings.
An AI-augmented workflow looks like this:
- Clinician uploads source documents (test results, interview notes, previous assessments).
- AI extraction pulls structured data from source documents using carefully crafted prompts designed for each test type.
- Extracted data populates structured forms.
- Clinician reviews and corrects the auto-filled forms (human verification step), optionally entering or importing more data manually.
- AI summarization synthesizes patterns across multiple data fields, flags noteworthy findings, and generates text using writing samples as style guides (this is key).
- Clinician reviews AI-generated narrative, adds clinical judgment and context, makes final edits (human expertise step).
- Report generation produces a precisely formatted document that serves as a first draft for final editing.
Below is a visual representation of parts of this data flow (steps 6-7 not shown):
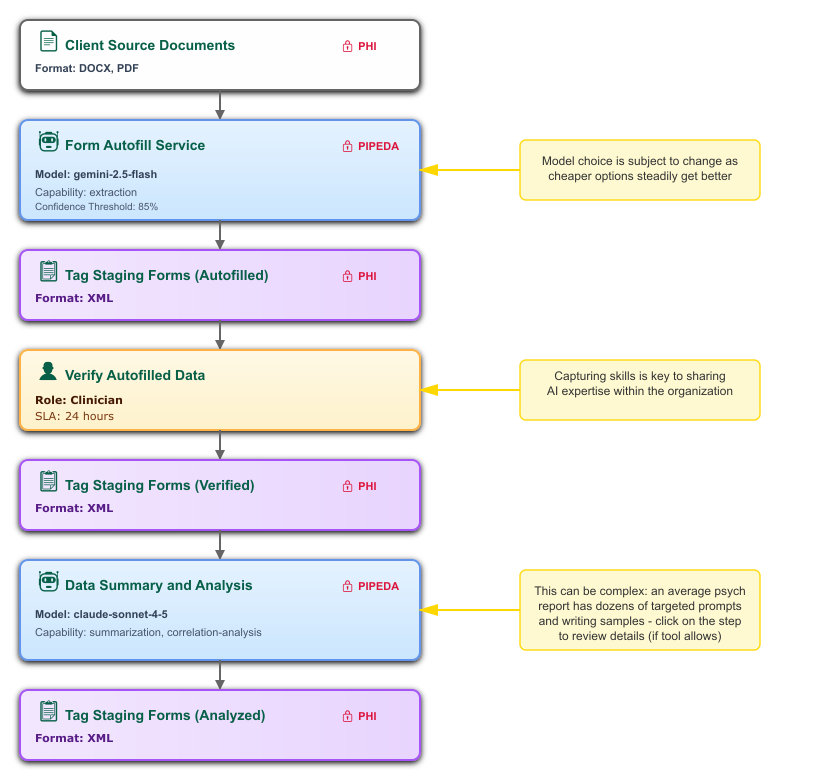
(The diagrams in this series were created by asking Claude to generate SVG graphics from text descriptions, a technique we'll explore in the next article.)
The entire flow is documented: which prompts extract what data, where writing samples guide AI tone, where human review is mandatory, and how protected health information is handled at each step.
This approach reduces report-writing time by as much as 80% while maintaining, and often improving, consistency. More importantly, it frees clinicians to focus on case conceptualization and interpretation rather than formatting, reorganization, and retyping.
Tools like nSymbol Tag demonstrate how AI can support these workflows while respecting both compliance and professional standards. As a desktop application that calls secure cloud services (like AWS Bedrock with Claude), it processes data locally and puts clinicians in control of file security, which is a critical requirement for HIPAA and PIPEDA compliance. The architecture allows practitioners to define exactly which data fields AI touches and which remain under direct human control, ensuring the professional always has final say over report content. (Note: Tag's Blueprint AI data modeling features are currently available through consulting engagements, while its workflow automation features (Scribe, Automate, and Dashboard) are publicly available. We'll explore Blueprint's capabilities further in the next article.)
Notably, the methodology outlined here doesn't depend on any specific tool. Whether you implement it with custom code, commercial platforms like Tag, or even careful documentation practices, the core concepts remain valid. The same principles apply to many document-intensive workflows: legal contract analysis, insurance claim processing, municipal permit reviews, engineering inspection reports. The details differ, but the framework transfers.
The Path Forward
AI data modeling isn't about discarding what you know because of AI - it's about extending it.
Your team's existing understanding of data security, integration challenges, and quality principles provides the foundation. We're adding new elements: AI capability patterns, prompt libraries, confidence thresholds, and human-AI handoffs.
Each organization's path will differ based on existing systems, data maturity, regulatory requirements, and strategic priorities. An insurance company has different AI opportunities than a city planning department, even though both will benefit from the same fundamental methodology.
Regardless of industry, organizations should consider establishing an AI Center of Excellence to support these efforts. A CoE consolidates AI expertise, ensures consistency across teams, promotes reuse, supports HR, and stays abreast of changes in the AI marketplace.
The key is making AI integration deliberate, documented, and repeatable. Here's where to start:
- Pick one workflow experiencing pain from unstructured data or repetitive interpretation, don't try to transform everything at once.
- Map current state using traditional flow concepts. Understand before you transform.
- Identify one AI capability that addresses a clear bottleneck. Start with extraction, classification, or summarization.
- Document end-to-end including the metadata this series describes: which models, which prompts, which humans review what, how sensitive data is protected.
- Measure and refine based on real results, not assumptions. Track time savings, error rates, and user satisfaction.
Many organizations find value in working with consultants for these initial implementations; not because the concepts are complex, but because establishing the right patterns prevents costly rework. The patterns you establish in your first implementation will propagate throughout your organization. Get them right once.
Over time, you build organizational capability: a shared understanding of how AI augments your operations, who has relevant skills, what patterns work, and how to implement safely. Your AI needs are guaranteed to change over time - plan for it with proper foundations.